Perspicacious AI - Speak to the Top G
AI-Powered semantic search over hours of YouTube podcasts and interviews from Andrew Tate 🚬💸💬
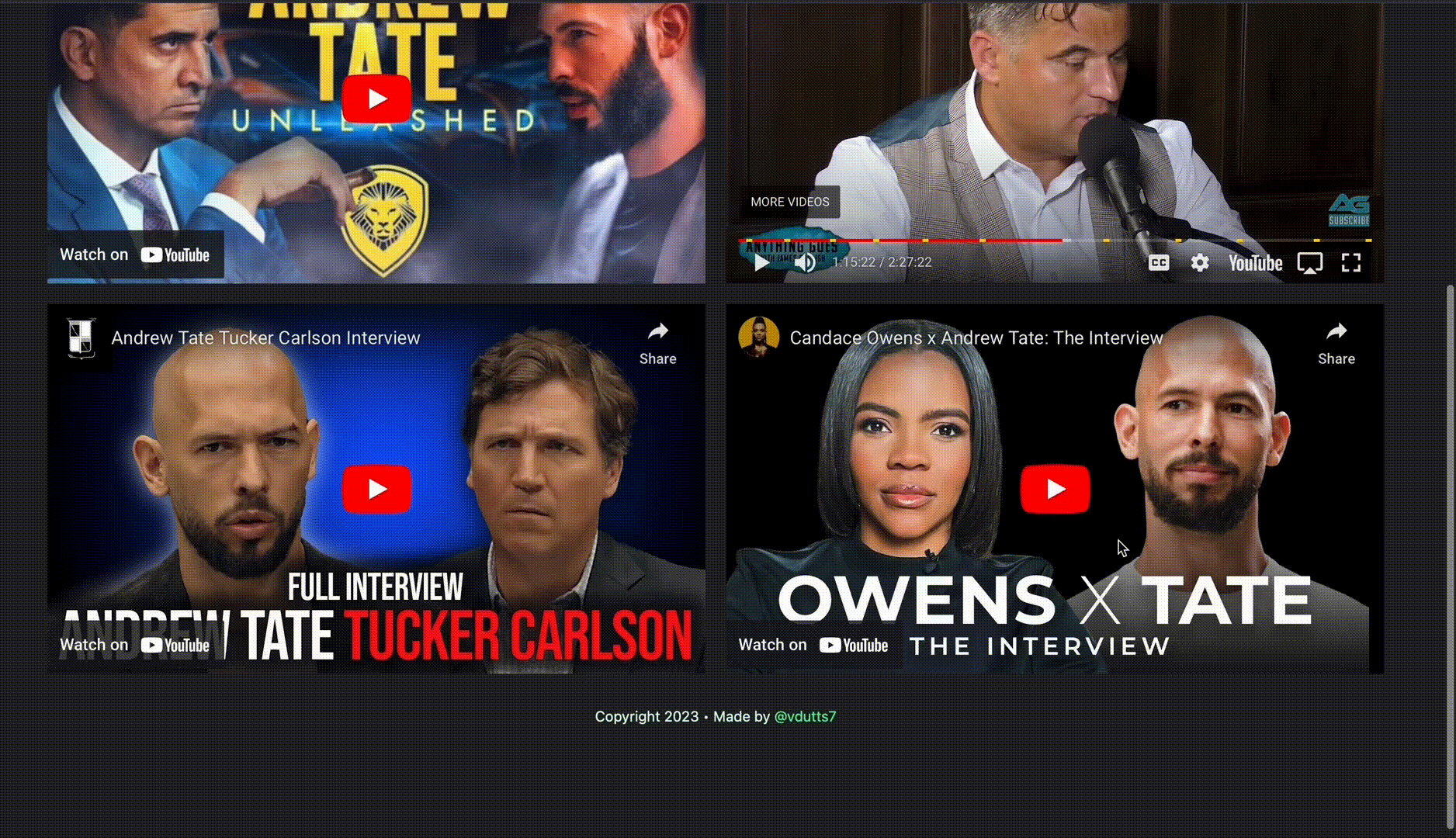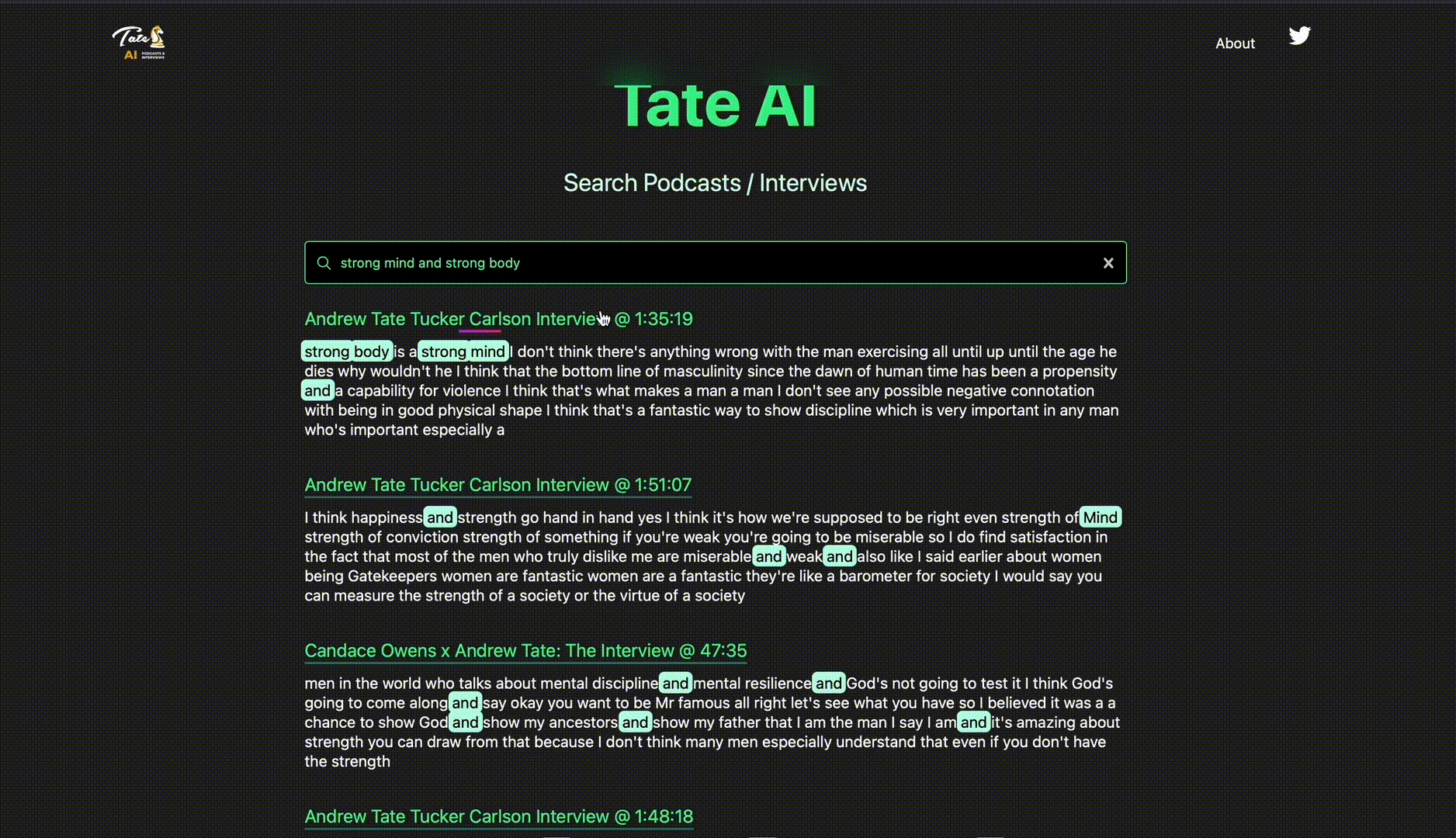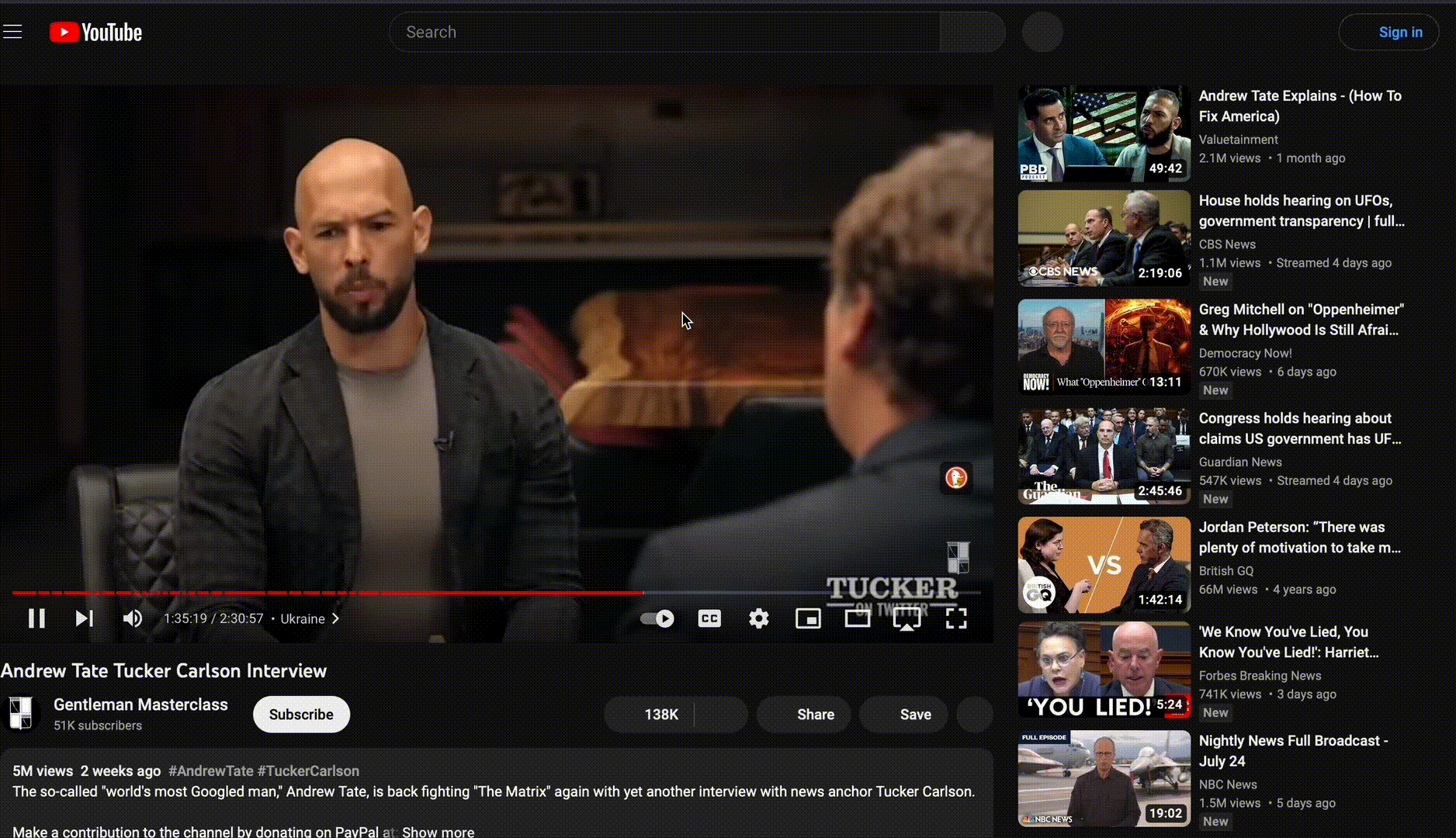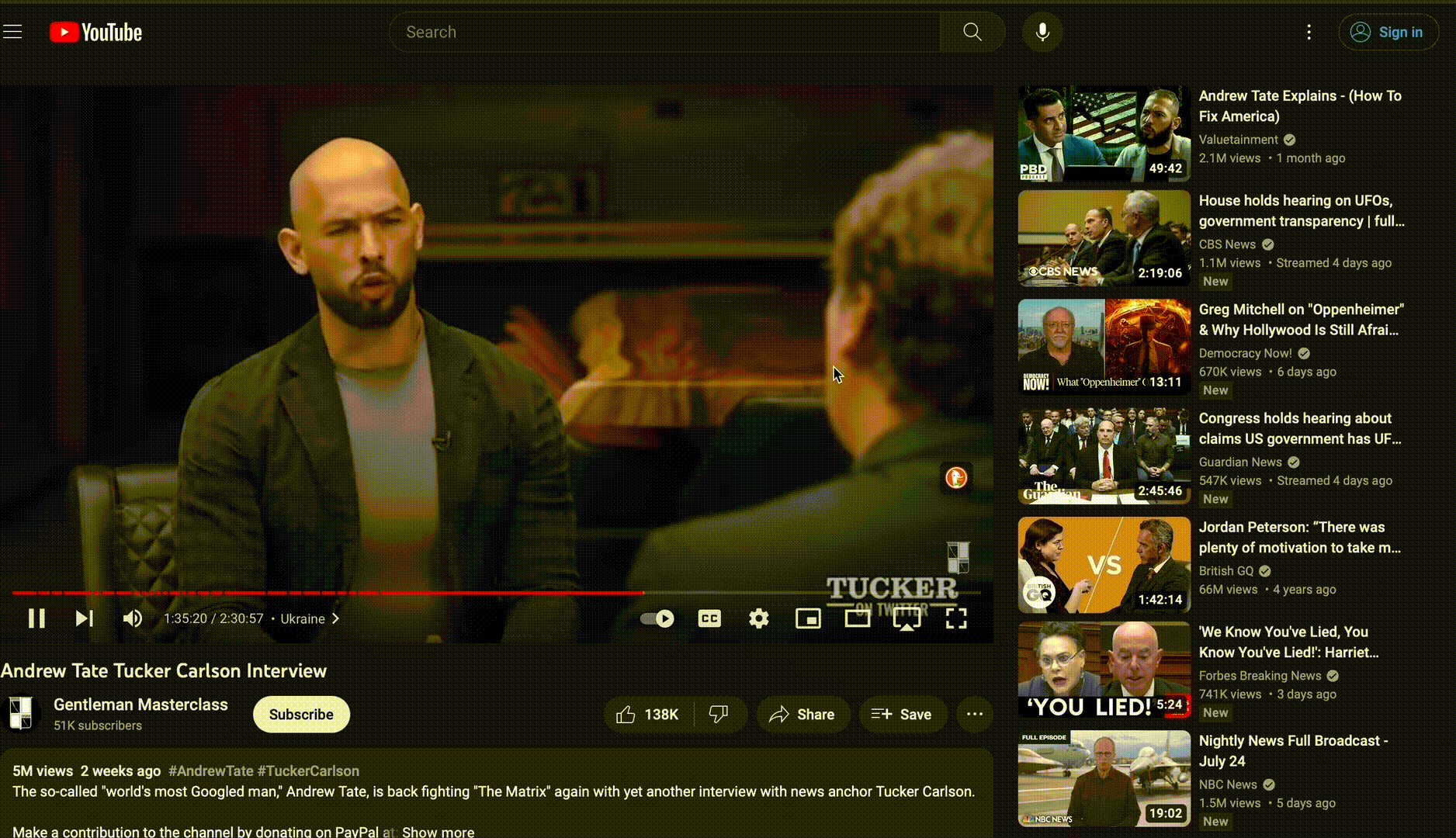
Table of Contents
📝About
AI semantic search over hours of podcasts and interviews on YouTube from Andrew Tate.
- Transcripts may not be perfect (blame YouTube API's stringent ban on non-OAuth caption access lol)
💻How to Build
This project uses basic Python scripts, a vector database, and a semantic k-nearest search (KNN).
- YouTube V3 API - Fetches and processes videos from YouTube to use as transcript backend powering semantic search.
- Milvus.io / Zilliz - vector DB backend storing video transcript data and powering semantic search for the frontend.
- OpenAI's text-embedding-ada-002 - used in conjunction with vector DB. Allows client more tools beyond basic keyword search. Read more on k-nearest-neighbor (KNN) algorithm.
Videos are transcribed using some hacky Python scripts, combined with associated metadata, and pre-processed (cleaned). The transcipts are chunked and vectorized into a database by tokens and converted to text embeddings with ~ 16k dimensions. There are limitations; for those who care more about this topic, read the Milvus documentation.
🚀Next Steps
Some of my plans to improve this project:
- Moving away from YouTube V3 API towards a faster transcribing solution. Whisper is good but expensive and pytube and other Python packages are probably going to be used once the amount of video content exceeds a certain storage capacity.
- Adding visual elements to search experience (i.e. thumnbail generation specific to the exact timestamp) using Puppeteer or some other solution.
🔧Tools Used
![]()
👤Contact